防衛省サイバーコンテスト事務局から成績票がメールで届きました。
一般•個人部門で108位/584人中でした。去年よりちょっと順位落としたかな。でもまぁ大会のレベルが上がっているので良しとするかな。
ちなみにこの前書いた参加記(所管)は「ここ」です。

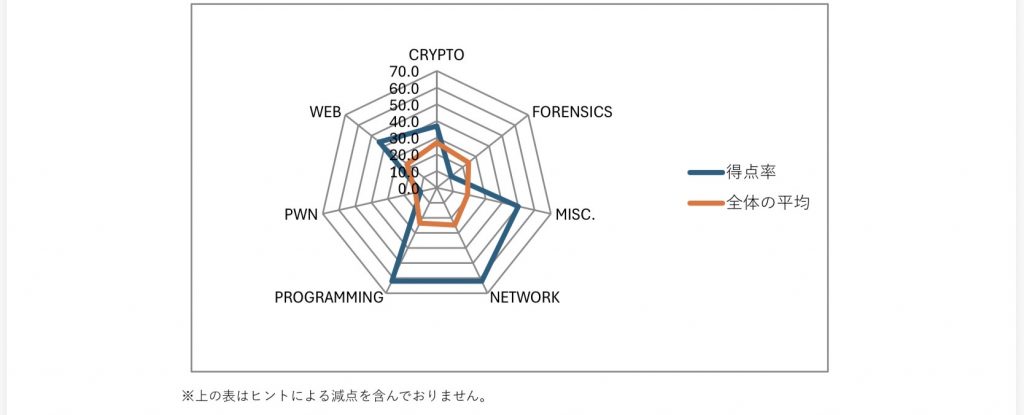
全体では 272位/987チーム中 という結果でした。
自分より上位にいたのは、チームというよりも、いわゆるツヨツヨな学生さんたちがかなり多かった印象です。
それでも、一般参加者と学生が混ざって競技できるのは、とても良いですね。
おじさんには良い刺激になります。機会があれば、若い人たちが多く参加している SECCON Beginners CTFにも挑戦してみたいところです。
さて、話題になっている AI の利用についてですが、競技終了後もしばらくは競技サイトにアクセスできていたので、LLM を使って再チャレンジしてみました。
さすがに AI エージェントの開発まではできていませんが、
「プロンプトを工夫して、うまく壁打ちできれば効率は上がるのでは?」と考え、以下の点に留意したプロンプトを AI に考えてもらいました。
- AI の役割
- 基本ルール
- 作業環境
- 結果の返却方法
- 禁止事項
- あきらめるタイミング
このプロンプトを使うと、確かにある程度は効率的に問題を解ける感触はありました。
ただ、30点問題については Forensic しか解けませんでした。 😭
自分の場合、ChatGPT は Plus プランですが、それ以外は無料プランなので、
やはり 使える LLM モデルの違い も影響しているのかもしれません。
……とはいえ、本音を言えば、単純に 自分のスキル不足 が一番の原因な気もしています。
それでも、一定の効果は確認できたので、いろいろ試してみる価値はありそうです。
Dify なども使えたりするのかな、と気になっています。
時間があれば、基本形で作ったプロンプトを OpenAI API で動かし、
さらに Function Calling を制御して MCP と組み合わせ、AI エージェントを構築。
そこで抽出したフラグを、別の LLM で動作する複数エージェント間で検証する…
最後はMCPで問題画面を読み取ったり、フラグを打ち込んだりする機能まで自動化する(ぼくには無理かな😆)
そんな構成も面白そうだなと思っています。
もっとも、現状では自分にノウハウがなく、構築はなかなか厳しそうですが 😅ツヨツヨな人のLLMはノウハウをLoRAで学習させたり、RAGで蓄積しているんでしょうね。そして、効率的な手順とかも組み込まれているんでしょうね。(さらにはかなり回数の検証をとっているんじゃないのかなぁ🤔「まさか、それも自動なのかな?」)
最近は Claude Code のように、A2A(Agent-to-Agent)を比較的簡単に実現できそうなツールも出てきていますし、
今後も次々に登場する新しいモデルやツールをしっかりウォッチしつつ、少しずつでも使いこなせるようになりたいな、と思う今日この頃です。(何を使うかも今後の検討ですね。)
まずは、Claudeに課金して、Claude Codeを使いこなせるようになるかな。