下部に2024.09.20メモ追記
いつも視聴しているYoutubeでRaspberry Piの4、5にローカルLLM(大規模言語モデル)をインストールするというのがあって、ちょっとやってみるかなと思って観ていたんだけど、Raspberry Piでは8Gのメモリが少ないことや、(やり方があるかもしれないけど)GPUが利用できないことが原因で、実用的ではないようだった。あと、MacBookAirでもやってて、そっちはいけてて、同じく、マシンスペックが要求されるようだったけど、Apple siliconのMacではCPUとGPUが同じメモリを共有しているとかで、色々と都合がいいらしい。
ということで、当初、入れようと思っていたRaspberry Piへの導入はあきらめて、MacBookPro💻に導入することにした。僕のMacBookProは、ひとつ前のモデルだけどディスク以外はフルスペックのM2Maxなので、大丈夫🙆。
あわせて、ゴールデンウィークで時間があるので、ついでにYoutubeではやっていなかったWebUI対応も追加で試してみることにした。(思ったよりスムーズにできて正直半日も作業をやってないけど🤣)
以下が手順
まずは、ローカルPC💻でLLMを実行するツールの「Ollama」をMacにインストール。下の画面の真ん中の「Download↓」ボタンからダウンロードして、ダウンロードしたアプリを起動してインストールを実行する。(インストール画面は無し)
その後、導入できるLLMは以下のページの「Models」にある。それぞれのモデルの説明もあり、実行方法(Macのターミナル用)もコピーできるようになっているので、コピペして実行すれば良い。そのまま、ターミナルのコマンドラインでも利用できるんだけど、WebでのUIとOllamaが連携できるというので、それも入れることにした。ちなみにパラメータ数の多いモデルを入れると数十分ぐらいのダウンロード時間と、実行するのにもかなりのメモリ容量が必要。(「Ollama」の操作については割愛)
Dockerは前からMacに入っていたので、そこにWebUIをインストールする。ターミナルのコマンドラインから以下のコマンドを入れて実行すればよい。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main実行するとDocker DesktopにWebUIのコンテナが実行中(Running)で表示される。
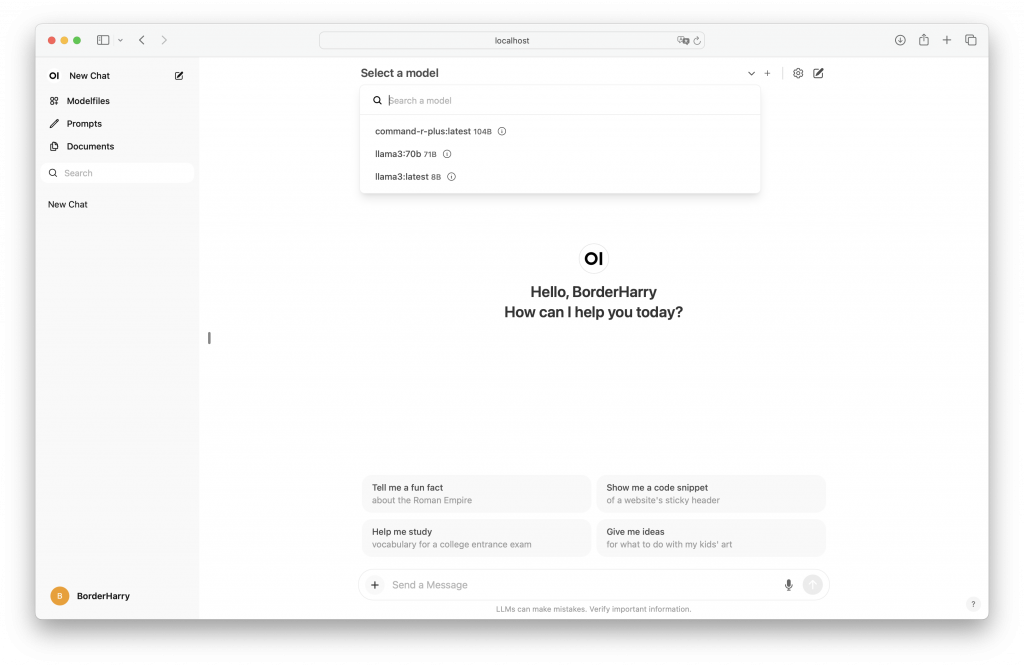
ブラウザからhttp://localhost:3000へアクセスすると以下のページが表示される。(というか、それより前にユーザ登録をしなきゃいけないんだけど、ローカルだし、適当に忘れない程度のユーザを作成しておく、僕の場合BorderHarry😸)
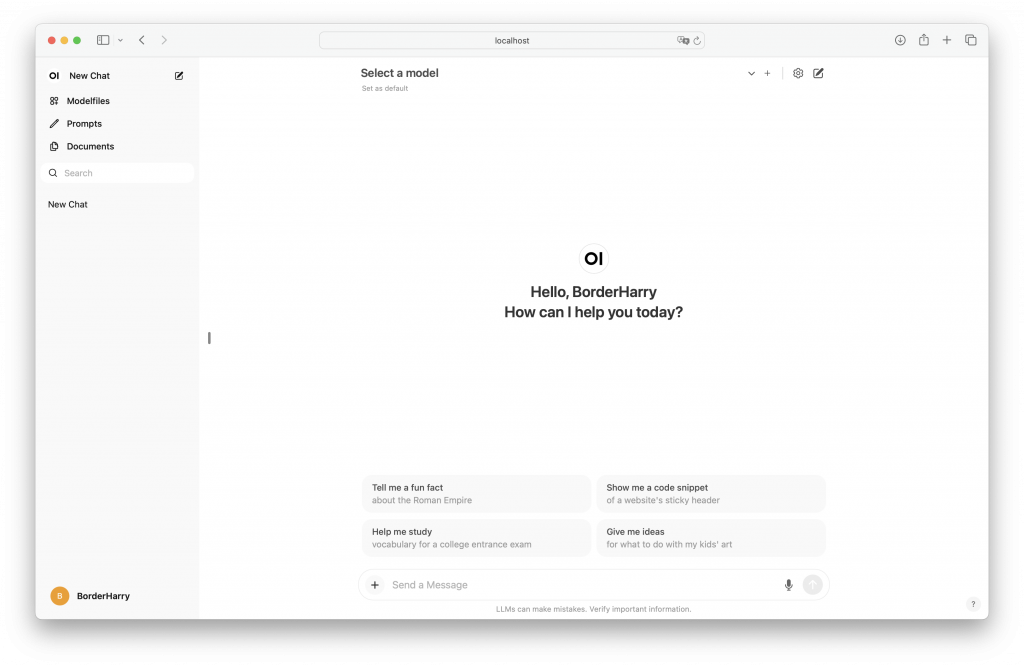
モデルの選択(Select a model)には事前にOllamaで入れておいた3つのモデルが表示されている。llama3 8B、llama3-70B、command-r-plus 104B-q4_0(Command R+)の3つ。
そして、それぞれについて試してみた。
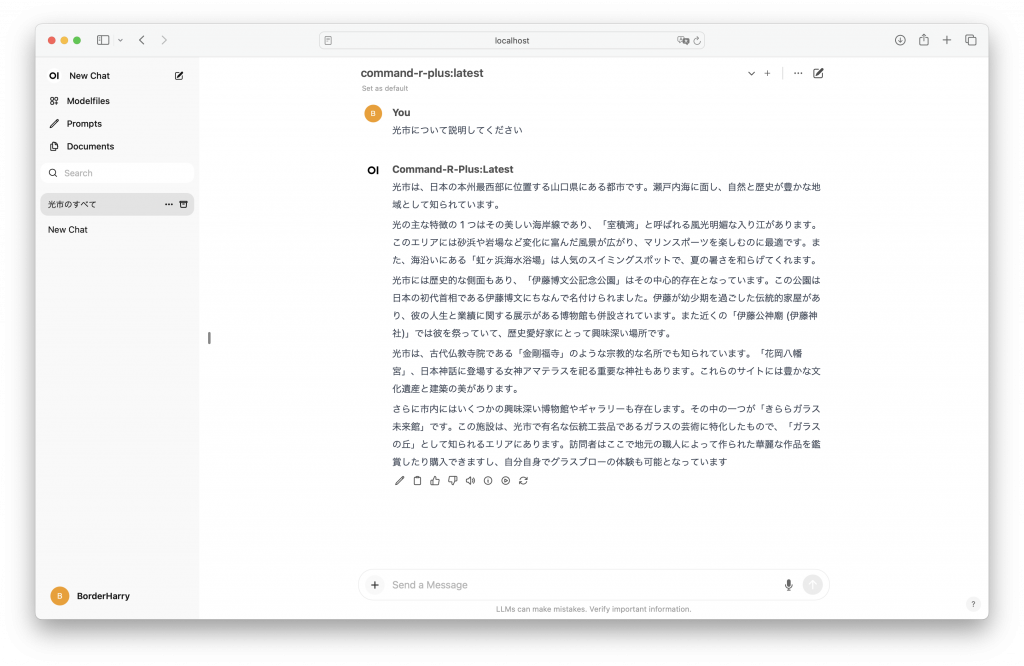
まずはCommand R+について、ちょっと最初の文字が出力されるまでタイムタグ(1分程度)あったけど、それは全てのモデルで言えることで、最初にモデルをメモリに全ロードするらしい。後からはスラスラと回答を出力した。日本語対応もしているみたいで特に指定しなくても日本語で回答してくれた。回答の内容については、後半部分が怪しい🤨感じがするけど、光市に住んでいながら検証とれない😅
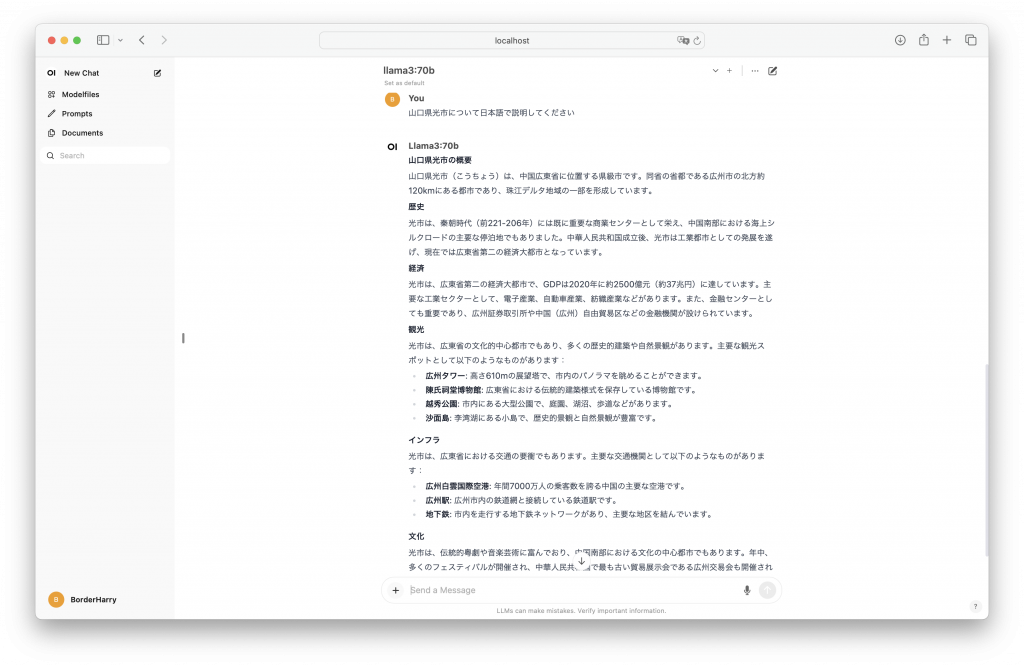
llama3 70Bは最初英語での回答で、しかも内容が完全に怪しかった。日本語で回答を求めると、中国🇨🇳がどうだとか?光市(「こうちょう」になってるし)のことがわかっていないようだった😭
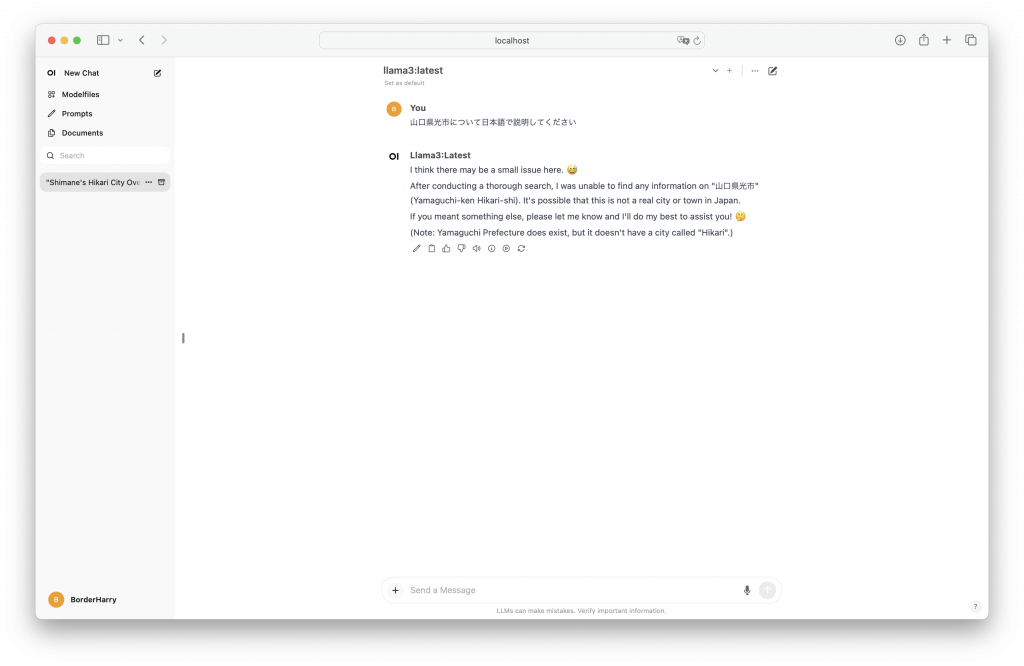
最後にllama 8Bを試すと、軽いだけあってこれが1番速攻で回答が出たけど、わからないということだった。(わからないから速かっただけかも?)
その後もいろいろ試して遊んでみた。今回の3つではCommand R+が1番賢い感じだった。
しかし、100Bクラスをオフラインで持ち運べて、ローカルで利用できるって‼️
この進歩、凄すぎ👀
今後は、RAGやファインチューニングを勉強して、自分の周辺に特化したモデルを利用でできるようになったらいいなぁと思う今日この頃である🧐
(後述、今回使ったCommand R+は浮動小数点を8bitの離散値に量子化しているらしい、量子化してもあんまり精度は変わらないという情報を見たりするんだけど、じゃぁ何が変わるんだと、なんだかよくわからなくなってきた😩。違うとどの程度の出力が違うのか、今度試してみたい。このあたりになると一般人の自分にはキツイ😓領域になるなぁ)